How can we recover data from Hard Drives were on RAID 10 without controller?
-
@scottalanmiller said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@PhlipElder said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@Dashrender said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@PhlipElder said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@Obsolesce said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@PhlipElder said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@manxam said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@PhlipElder : Why did you stop deploying RAID 10? It's about the most fault tolerant and performance oriented RAID config one can get for hardware RAID.
Nope.
Had a virtualization host RAID 10 drive, of six, die.
I popped by, did a hot swap of the dead drive, rebuild started, and I sat for a coffee with the on-site IT person.
About 5 minutes into that coffee we heard a BEEP, BEEP-BEEP, and then nothing. It was sitting at the RAID POST prompt indicating failed array and no POST.
It's pair had died too.
I'll stick with RAID 6 thank you very much. We'd still have had the server.
We ended up installing a fresh OS, setting things up, and recovering from backup (ShadowProtect) after flattening and setting up the array again.
You can't say that. There's way more work being done on the drives with a RAID6, maybe then 3 or 4 drives would have went out close together instead of just two. If you think a RAID10 was the cause of 2 drives dieing, then holy shit a RAID 6 woulda killed 3+.
My guesses are one or more of the folowing:
- a bad batch of drives
- wrong drives
- drives used past their warranty/expectancy or whatever
- lack of monitoring
And by the way, a RAID 10 isn't really a "rebuild". It's not a very disk intensive thing like it is with a RAID 6.
Please re-read what I wrote and stop interpreting it.
I'm curious where he got it wrong? RAID 10's are considered ridiculously reliable. The most likely reason for a failure of two drives in a RAID 10 is a single batch of drives - so they all or several reach failure at the same time.
A drive is a drive. It's a piece of machinery prone to failure just like any other. Period.
During the rebuild, it's partner does indeed get stressed as it handles both regular work and the read calls for its partner to write to. So, bunk on that.
Statiatically RAID 10 is reliable to an absurd degree. Even with drive technology generations old. Its so statistically reliable its incalculable.
Guess my experience kinda blows that assumption out of the water eh?
")
-
@PhlipElder said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@manxam said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@PhlipElder : Why did you stop deploying RAID 10? It's about the most fault tolerant and performance oriented RAID config one can get for hardware RAID.
Nope.
Had a virtualization host RAID 10 drive, of six, die.
I popped by, did a hot swap of the dead drive, rebuild started, and I sat for a coffee with the on-site IT person.
About 5 minutes into that coffee we heard a BEEP, BEEP-BEEP, and then nothing. It was sitting at the RAID POST prompt indicating failed array and no POST.
It's pair had died too.
I'll stick with RAID 6 thank you very much. We'd still have had the server.
We ended up installing a fresh OS, setting things up, and recovering from backup (ShadowProtect) after flattening and setting up the array again.
In that example, for which we would need a lot more info to understand, you cant say raid 6 would have survived. It may have died too.
Questions about how long was the remaining drive left before the replacement provided, were they damaged, was it actually controller failure, etc.
Ive had raid 1 fail recently, but it was the controller not the drives.
Mathematically and from research, raid 10 is safe to a degree that makes it safe, when operated correctly, to a point that you never actually need to worry about it. And raid 6 is mathematically less safe.
Using an anecdote, especially one where the key factors arent mentioned, doesnt even remotely suggest that avoiding raid 10 is a proper takeaway, or that using raid 6 is better, or that raid 6 would have protected you, or if it did that it wasnt a fluke.
Regardless of there being a possible anecdote to where raid 10 failed, your response to it suggests that you were expecting it to be impossible to fail, which doesnt make sense. Its implaussible to fail, thats not the same.
A similar reaction would be to avoid flying because you had been in a crash. But that you were in a rare crash doesnt change that driving is more dangerous than flying. Its a misunderstanding of how to apply the lesson learned.
-
@PhlipElder said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@Dashrender said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@PhlipElder said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@Obsolesce said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@PhlipElder said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@manxam said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@PhlipElder : Why did you stop deploying RAID 10? It's about the most fault tolerant and performance oriented RAID config one can get for hardware RAID.
Nope.
Had a virtualization host RAID 10 drive, of six, die.
I popped by, did a hot swap of the dead drive, rebuild started, and I sat for a coffee with the on-site IT person.
About 5 minutes into that coffee we heard a BEEP, BEEP-BEEP, and then nothing. It was sitting at the RAID POST prompt indicating failed array and no POST.
It's pair had died too.
I'll stick with RAID 6 thank you very much. We'd still have had the server.
We ended up installing a fresh OS, setting things up, and recovering from backup (ShadowProtect) after flattening and setting up the array again.
You can't say that. There's way more work being done on the drives with a RAID6, maybe then 3 or 4 drives would have went out close together instead of just two. If you think a RAID10 was the cause of 2 drives dieing, then holy shit a RAID 6 woulda killed 3+.
My guesses are one or more of the folowing:
- a bad batch of drives
- wrong drives
- drives used past their warranty/expectancy or whatever
- lack of monitoring
And by the way, a RAID 10 isn't really a "rebuild". It's not a very disk intensive thing like it is with a RAID 6.
Please re-read what I wrote and stop interpreting it.
I'm curious where he got it wrong? RAID 10's are considered ridiculously reliable. The most likely reason for a failure of two drives in a RAID 10 is a single batch of drives - so they all or several reach failure at the same time.
A drive is a drive. It's a piece of machinery prone to failure just like any other. Period.
During the rebuild, it's partner does indeed get stressed as it handles both regular work and the read calls for its partner to write to. So, bunk on that.
There is stress. But trivial stress on one drive versus heavy stress on many. The time and workload differences are huge.
They arent comparable stresses. Very big numerical differences.
-
@Dashrender said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@PhlipElder said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@Obsolesce said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@PhlipElder said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@manxam said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@PhlipElder : Why did you stop deploying RAID 10? It's about the most fault tolerant and performance oriented RAID config one can get for hardware RAID.
Nope.
Had a virtualization host RAID 10 drive, of six, die.
I popped by, did a hot swap of the dead drive, rebuild started, and I sat for a coffee with the on-site IT person.
About 5 minutes into that coffee we heard a BEEP, BEEP-BEEP, and then nothing. It was sitting at the RAID POST prompt indicating failed array and no POST.
It's pair had died too.
I'll stick with RAID 6 thank you very much. We'd still have had the server.
We ended up installing a fresh OS, setting things up, and recovering from backup (ShadowProtect) after flattening and setting up the array again.
You can't say that. There's way more work being done on the drives with a RAID6, maybe then 3 or 4 drives would have went out close together instead of just two. If you think a RAID10 was the cause of 2 drives dieing, then holy shit a RAID 6 woulda killed 3+.
My guesses are one or more of the folowing:
- a bad batch of drives
- wrong drives
- drives used past their warranty/expectancy or whatever
- lack of monitoring
And by the way, a RAID 10 isn't really a "rebuild". It's not a very disk intensive thing like it is with a RAID 6.
Please re-read what I wrote and stop interpreting it.
I'm curious where he got it wrong? RAID 10's are considered ridiculously reliable. The most likely reason for a failure of two drives in a RAID 10 is a single batch of drives - so they all or several reach failure at the same time.
That's true - sort of. But the single batch problem is a red herring. Even in a single defective batch failures normally occur very far apart. Its statistically almost impossible for the batch problem to cause a RAID 1 failure alone.
Almost all double drive failures come from long replacement times between failure and resilver. If replaced promptly, the batch problem effectively doesnt exist. People talk about it, but its not real.
But those are how double drives fail, which all but never happens. In the real world, controller, backplane, and connection failures - which often look like and behave like double drive failure - are what people often experience. This is most commonly caused by vibrations or similar causing drives to enter and leave an array.
Ive seen it on all kinds of arrays. RAID 1 just last week. If no one analysed the drives theyd think we had double drive failure. But we didnt. A drive just left and rejoined from vibration in a bad order and got overwritten. The physical drive didnt fail.
This failure affects all array types and is far more common than disk failures in most environments.
-
@scottalanmiller said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@PhlipElder said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@Dashrender said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@PhlipElder said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@Obsolesce said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@PhlipElder said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@manxam said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@PhlipElder : Why did you stop deploying RAID 10? It's about the most fault tolerant and performance oriented RAID config one can get for hardware RAID.
Nope.
Had a virtualization host RAID 10 drive, of six, die.
I popped by, did a hot swap of the dead drive, rebuild started, and I sat for a coffee with the on-site IT person.
About 5 minutes into that coffee we heard a BEEP, BEEP-BEEP, and then nothing. It was sitting at the RAID POST prompt indicating failed array and no POST.
It's pair had died too.
I'll stick with RAID 6 thank you very much. We'd still have had the server.
We ended up installing a fresh OS, setting things up, and recovering from backup (ShadowProtect) after flattening and setting up the array again.
You can't say that. There's way more work being done on the drives with a RAID6, maybe then 3 or 4 drives would have went out close together instead of just two. If you think a RAID10 was the cause of 2 drives dieing, then holy shit a RAID 6 woulda killed 3+.
My guesses are one or more of the folowing:
- a bad batch of drives
- wrong drives
- drives used past their warranty/expectancy or whatever
- lack of monitoring
And by the way, a RAID 10 isn't really a "rebuild". It's not a very disk intensive thing like it is with a RAID 6.
Please re-read what I wrote and stop interpreting it.
I'm curious where he got it wrong? RAID 10's are considered ridiculously reliable. The most likely reason for a failure of two drives in a RAID 10 is a single batch of drives - so they all or several reach failure at the same time.
A drive is a drive. It's a piece of machinery prone to failure just like any other. Period.
During the rebuild, it's partner does indeed get stressed as it handles both regular work and the read calls for its partner to write to. So, bunk on that.
There is stress. But trivial stress on one drive versus heavy stress on many. The time and workload differences are huge.
They arent comparable stresses. Very big numerical differences.
on a single drive POV, what is the difference in stress level, and what causes it?
-
@Dashrender said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@scottalanmiller said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@PhlipElder said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@Dashrender said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@PhlipElder said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@Obsolesce said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@PhlipElder said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@manxam said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@PhlipElder : Why did you stop deploying RAID 10? It's about the most fault tolerant and performance oriented RAID config one can get for hardware RAID.
Nope.
Had a virtualization host RAID 10 drive, of six, die.
I popped by, did a hot swap of the dead drive, rebuild started, and I sat for a coffee with the on-site IT person.
About 5 minutes into that coffee we heard a BEEP, BEEP-BEEP, and then nothing. It was sitting at the RAID POST prompt indicating failed array and no POST.
It's pair had died too.
I'll stick with RAID 6 thank you very much. We'd still have had the server.
We ended up installing a fresh OS, setting things up, and recovering from backup (ShadowProtect) after flattening and setting up the array again.
You can't say that. There's way more work being done on the drives with a RAID6, maybe then 3 or 4 drives would have went out close together instead of just two. If you think a RAID10 was the cause of 2 drives dieing, then holy shit a RAID 6 woulda killed 3+.
My guesses are one or more of the folowing:
- a bad batch of drives
- wrong drives
- drives used past their warranty/expectancy or whatever
- lack of monitoring
And by the way, a RAID 10 isn't really a "rebuild". It's not a very disk intensive thing like it is with a RAID 6.
Please re-read what I wrote and stop interpreting it.
I'm curious where he got it wrong? RAID 10's are considered ridiculously reliable. The most likely reason for a failure of two drives in a RAID 10 is a single batch of drives - so they all or several reach failure at the same time.
A drive is a drive. It's a piece of machinery prone to failure just like any other. Period.
During the rebuild, it's partner does indeed get stressed as it handles both regular work and the read calls for its partner to write to. So, bunk on that.
There is stress. But trivial stress on one drive versus heavy stress on many. The time and workload differences are huge.
They arent comparable stresses. Very big numerical differences.
on a single drive POV, what is the difference in stress level, and what causes it?
It's not single drive, that's part of the issue.
RAID 10 does a straight read on one drive worth of data. It's very simple and straightforward, it's a mirror operation. That's stress, but it's the lightest stress that you can have.
RAID 6 requires non-straight reads from all drives in the array. So that's N-1 stress with a minimum being three drives (we don't count the one being written to) under more stressful load. So the chances of killing another drive from stress ranges from around 350% to easily 3,000% depending on the size of the array - assuming otherwise idle.
If there is any load on the array, then the degree to which parity RAID is impacted increases because of the complexity of the changing load and the obvious lower performance already in place.
-
@scottalanmiller said in How can we recover data from Hard Drives were on RAID 10 without controller?:
RAID 6 requires non-straight reads from all drives in the array. So that's N-1 stress with a minimum being three drives (we don't count the one being written to) under more stressful load. So the chances of killing another drive from stress ranges from around 350% to easily 3,000% depending on the size of the array - assuming otherwise idle.
That is incorrect, you must be thinking about something else.
Below are the stripe layout on a RAID-6. P and Q are parity, 1 to 3 are actual data.
The first row A, is the stripe so they belong together. Then B, C etc.So to rebuild disk 1, the stripe A on disk 2, 3, 4, 5 are read at the same time and as soon as the data is in, the missing data is calculated (XOR) and written to disk 1. While that happens the next stripe B is read. And so on and so forth.
So it's a pure sequential read on all drives in the array and a sequential write on the drive being rebuilt. Starting from the outside of the disk platters and moving in.
Only thing that would interrupt this sequential operation is other I/O operations on the array, but that is true for all types of raid arrays.
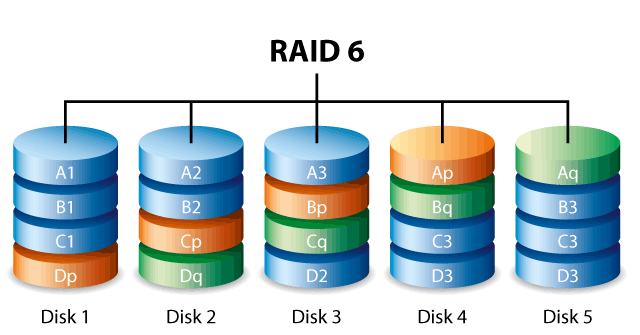
PS. The astute reader will notice that there are three errors in the image above from Seagate. -
@Pete-S said in How can we recover data from Hard Drives were on RAID 10 without controller?:
So it's a pure sequential read on all drives in the array and a sequential write on the drive being rebuilt. Starting from the outside of the disk platters and moving in.
Can't be sequential because it has to skip over the parity, it's nearly sequential, but not quite. And if there is any production traffic, all sequential is gone.
-
@Pete-S said in How can we recover data from Hard Drives were on RAID 10 without controller?:
Only thing that would interrupt this sequential operation is other I/O operations on the array, but that is true for all types of raid arrays.
Yes, that affects all types. But as mirror recreation is so much faster typically (from hours to months faster depending on drives and controllers and activity) you often get to rebuild mirrors with low or no load, and parity almost always gets hit with production load.
-
@scottalanmiller said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@Pete-S said in How can we recover data from Hard Drives were on RAID 10 without controller?:
Only thing that would interrupt this sequential operation is other I/O operations on the array, but that is true for all types of raid arrays.
Yes, that affects all types. But as mirror recreation is so much faster typically (from hours to months faster depending on drives and controllers and activity) you often get to rebuild mirrors with low or no load, and parity almost always gets hit with production load.
Yup, I did a RAID5 rebuild that took well over a month. Couldn't help it, it had to stay in production because contained too much data to keep it down long enough to rebuild at 100%, as that still would have taken weeks. I tried to rebuild another another RAID 5 too, but gave up after a few weeks. It was still faster at that point to set up something else and migrate/sync the data over and start over.
Again, couldn't image them being a RAID 6. There's no way they'd have survived a rebuild.
-
@Obsolesce said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@scottalanmiller said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@Pete-S said in How can we recover data from Hard Drives were on RAID 10 without controller?:
Only thing that would interrupt this sequential operation is other I/O operations on the array, but that is true for all types of raid arrays.
Yes, that affects all types. But as mirror recreation is so much faster typically (from hours to months faster depending on drives and controllers and activity) you often get to rebuild mirrors with low or no load, and parity almost always gets hit with production load.
Yup, I did a RAID5 rebuild that took well over a month. Couldn't help it, it had to stay in production because contained too much data to keep it down long enough to rebuild at 100%, as that still would have taken weeks. I tried to rebuild another another RAID 5 too, but gave up after a few weeks. It was still faster at that point to set up something else and migrate/sync the data over and start over.
Again, couldn't image them being a RAID 6. There's no way they'd have survived a rebuild.
I've had clients on RAID 6 top two months. Once you have a rebuild go over 48 hours, it's a very, very rare shop that can both justify attempting a rebuild and doesn't have to keep it in production while doing so.
In a lab environment where you don't have real world time constraints, the results are much closer. And if you have software RAID and can throw loads of CPU at it, it speeds up. But I've never seen real world conditions where they can do that to a workload that also needs to rebuild.
And then it adds all those other failures, too. Disk failure isn't the main one on spinners, there is just so much to go wrong.
It's so big of a problem that we used to see shops routinely refuse disk replacements until the weekends because they knew it would take too long, and that it would be impactful. So on top of other concerns, it also turned what should have been a 15 minute mean time to drive replacement into a 50 hours mean time to drive replacement. Which obviously takes the chances of failure through the roof.
-
@scottalanmiller said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@Pete-S said in How can we recover data from Hard Drives were on RAID 10 without controller?:
So it's a pure sequential read on all drives in the array and a sequential write on the drive being rebuilt. Starting from the outside of the disk platters and moving in.
Can't be sequential because it has to skip over the parity, it's nearly sequential, but not quite. And if there is any production traffic, all sequential is gone.
It makes sense to believe that, since RAID-6 only needs data from N-2 drives to recreate what's missing.
However it reads from all drives because it's much faster to calculate the missing data when you have N-1. It's a math thing. If you check the source code for the md driver in the kernel you'll see it mentioned several times.The other factor is that it is head movements that destroys the sequential performance. The drive that had the data you could calculate, instead of reading, is just spinning. It doesn't do anything else and can't do anything by itself. So you won't lose anything even if you'd skip one stripe segment on one drive. It wouldn't lower the performance of the rebuild except increasing the amount of data that need to be calculated.
-
@Pete-S said in How can we recover data from Hard Drives were on RAID 10 without controller?:
However it reads from all drives because it's much faster to calculate the missing data when you have N-1. It's a math thing. If you check the source code for the md driver in the kernel you'll see it mentioned several times.
Oh right, because it's a different calc each time. One time it's p, one time it's q, one time it's 1 and so forth.
-
@scottalanmiller said in How can we recover data from Hard Drives were on RAID 10 without controller?:
@Pete-S said in How can we recover data from Hard Drives were on RAID 10 without controller?:
However it reads from all drives because it's much faster to calculate the missing data when you have N-1. It's a math thing. If you check the source code for the md driver in the kernel you'll see it mentioned several times.
Oh right, because it's a different calc each time. One time it's p, one time it's q, one time it's 1 and so forth.
Yes, and it's the double parity (Q) that is very costly in CPU to calculate. The actual math for the double parity is advanced stuff, way beyond me. But if you have one failed drive you only have to do the double parity calculation every N stripes to be able to rebuild the drive. If you have two failed drives you have to do it every stripe. That's why it's less CPU/energy/heat consuming to just read all the drives when rebuilding.
In general I think that people who have problems rebuilding RAID-6 arrays have two problems.
- They just pop in the replacement drive and wait. Not knowing that they need to adjust the rebuild priority unless they want to wait forever.
- They made a design fail, ie wrong type / size of array for the job in question. And now they're paying the price.
RAID-6 arrays also have a tendency to big large arrays with large drives, exacerbating the problem.
And I think people are over-consolidating in their excitement to consolidate everything. Basically ending up with all the eggs in one basket.
-
@Pete-S said in How can we recover data from Hard Drives were on RAID 10 without controller?:
Yes, and it's the double parity (Q) that is very costly in CPU to calculate. The actual math for the double parity is advanced stuff, way beyond me. But if you have one failed drive you only have to do the double parity calculation every N stripes to be able to rebuild the drive.
Yeah, I was trying to allude to that in what I had said. Only when replacing the P, I think, it needs that.
-
@Pete-S said in How can we recover data from Hard Drives were on RAID 10 without controller?:
They just pop in the replacement drive and wait. Not knowing that they need to adjust the rebuild priority unless they want to wait forever.
Or.... they should have their rebuild priorities adjusted as a standard based on the assumed workload needs and only adjust later if something special has happened.
-
@Pete-S said in How can we recover data from Hard Drives were on RAID 10 without controller?:
RAID-6 arrays also have a tendency to big large arrays with large drives, exacerbating the problem.
This is a complex logic. It's something like...
Large arrays tend to use spinners. Spinners tend to use RAID 6 or 10. Large arrays tend to be costly for RAID 10. etc.
But a huge selling point for RAID 10 is that recovery time is flat. Keep adding drives, the recovery time doesn't change. RAID 6, every additional drive can add a bit of time.
-
@Pete-S said in How can we recover data from Hard Drives were on RAID 10 without controller?:
And I think people are over-consolidating in their excitement to consolidate everything. Basically ending up with all the eggs in one basket.
We see this a lot. There is certainly a desire for "one pool of storage" and it's so easy now that 10TB drives are so cheap. Heck, I bought one for my kids' video games. 10TB Helium 6Gb/s SATA drive with 256MB cache on my children's video game machine!
-
Have you checked the SMART values to make sure the drives are degraded and bad? If the drives are good a simple chkdsk may resolve your issues
-
This post is deleted!